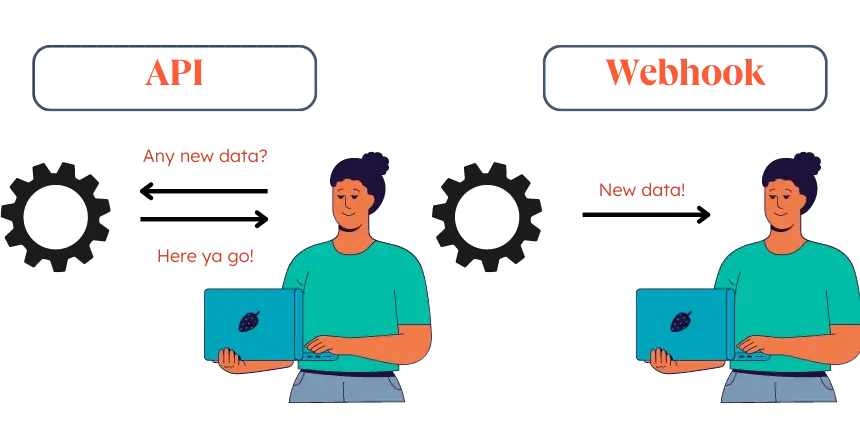
La plupart des outils de données infèrent comment lire vos données. Voici pourquoi c'est à la racine de chaque corruption de pipeline que j'ai vue.
L'inférence ressemble à une fonctionnalité jusqu'à ce qu'elle corrompe silencieusement une migration et que les chiffres cessent de correspondre trois mois plus tard. Voici une analyse technique expliquant pourquoi la normalisation basée sur l'inférence est structurellement incorrecte pour des sources de données imprévisibles, et la décision architecturale qui élimine le problème entièrement.
6 avril 2026|