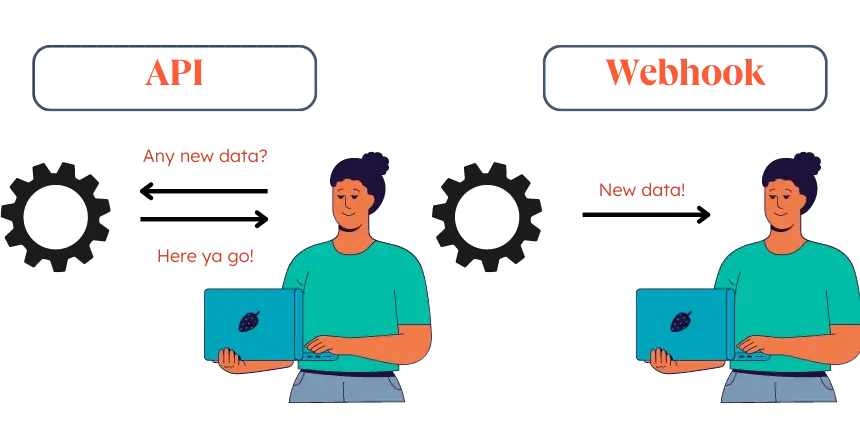
Most data tools infer how to read your data. Here's why that's the root of every pipeline corruption I've seen.
Inference feels like a feature until it corrupts a migration silently and the numbers stop matching three months later. This is a technical breakdown of why inference-based normalization is structurally wrong for unpredictable data sources, and the architectural decision that eliminates the problem entirely.
April 6, 2026|